Bert之後的進展?總結各種模型的想法與方向
Bert出來都有一段不短的時間了,這段時間NLP界狂暴式地發展,各種模型和方法讓人目不暇接。在這裡整理了近期的進展和相關的資源,也可以藉此猜想往後的方向。
如果是對Bert不太瞭解的話,可以先參考看看之前的文章:
https://voidful.github.io/voidful_blog/implement/2019/06/05/bert-implement-101/
接下來會從以下方向去探討:
- 預訓練的方式
- MaskedLM 改善 - 加大範圍
- 改變Masked的比例
- NextSentencePrediction 👎?
- 其他pre-train task
- 輕量化
- 剪枝
- 矩陣分解
- 參數共享
- 多語言
- 更大的模型,更好的結果?
- 多任務
- 相關中文project
預訓練的方式
Bert這個模型為什麼會引起那麼大的變革,是由於他改變NLP DL模型的訓練方式。先是用大規模的語料訓練一個學習語意的模型,再用這個模型去做特定任務 - 閱讀理解/情緒分類/NER…..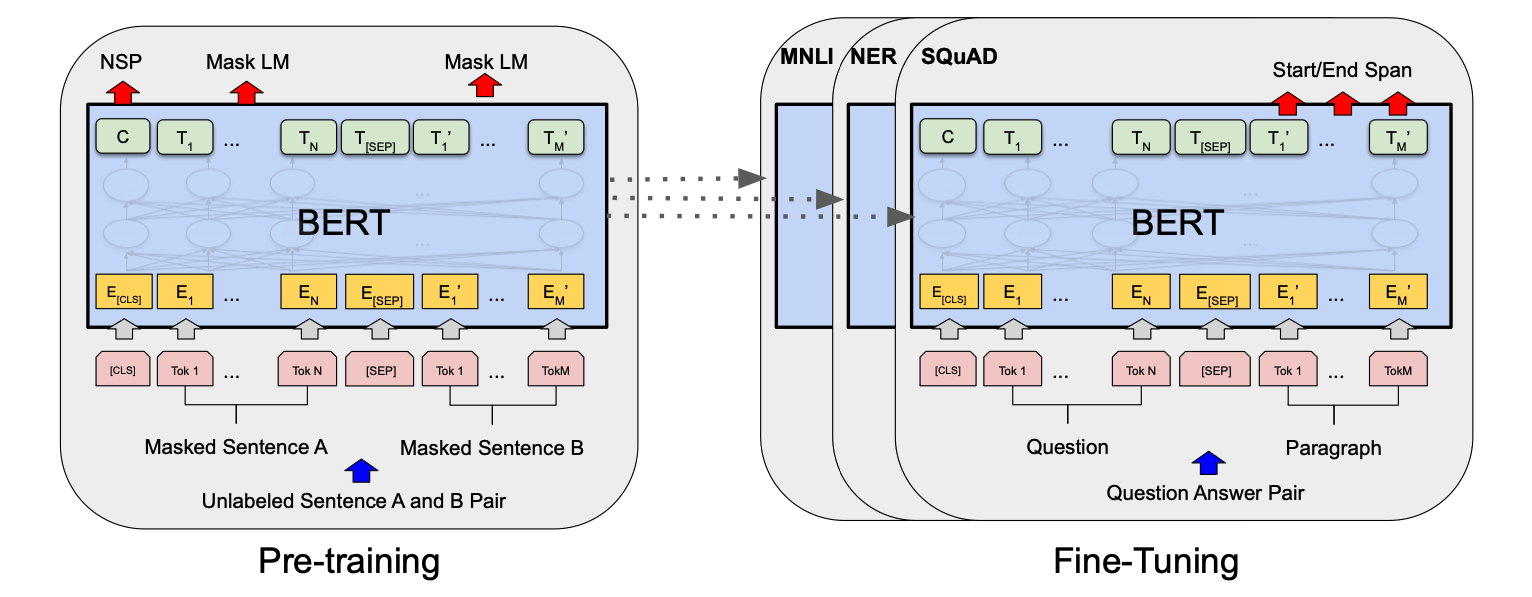
這種方式也被Yann LeCun叫做self-supervises learning
在Bert上,學習語意的模型是一個基於Transformer Encoder的多任務模型,做的兩個任務分別是 MaskedLM 和 NextSentencePrediction。
要改善Bert,其中一個直覺的想法,就是從預訓練的任務入手:
MaskedLM 改善 - 加大範圍
MaskedLM中,會只對一個字做MASK,由於字與字和詞語間的關聯性是不一樣的,Bert可能沒辦法學到詞組跟字的聯繫。如蝙蝠一起出現的機率很高,我們單獨預測 蝙 或者 蝠 的意義不大,反而是預測整串 蝙蝠 更加能學到其語義。
因此,擴大masking的範圍就勢在必行,而且範圍還一級一級往上增長:
WordPiece會把一個英文單詞斷開,因此要在完整單詞上Masking的 - Google wwm
有在Word/Phrase層級上masking - 百度的ERNIE
擴大到一定長度的片段 - Google的Ngram Masking 和 Span Masking
Word/Phrase層級需要提供相對應的詞表,這些人工加入的訊息可以會擾亂到模型,或者給模型一個bias。這個缺點看來,擴大到一定長度的片段應是一個比較好的解決方法,但T5對不同長度的片段做masking得出這樣的結論: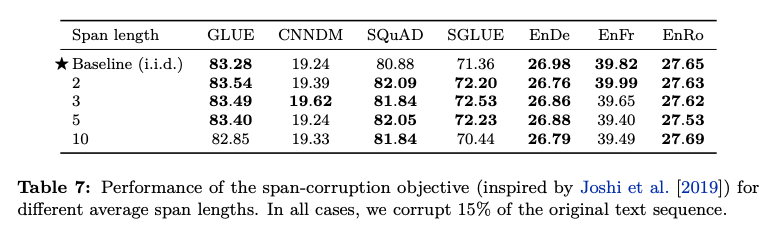
可以看出,加大長度說有效果的,但並不代表越長越好。SpanBert透過機率取樣,減少Mask過長文本的機率是不錯的解決方法。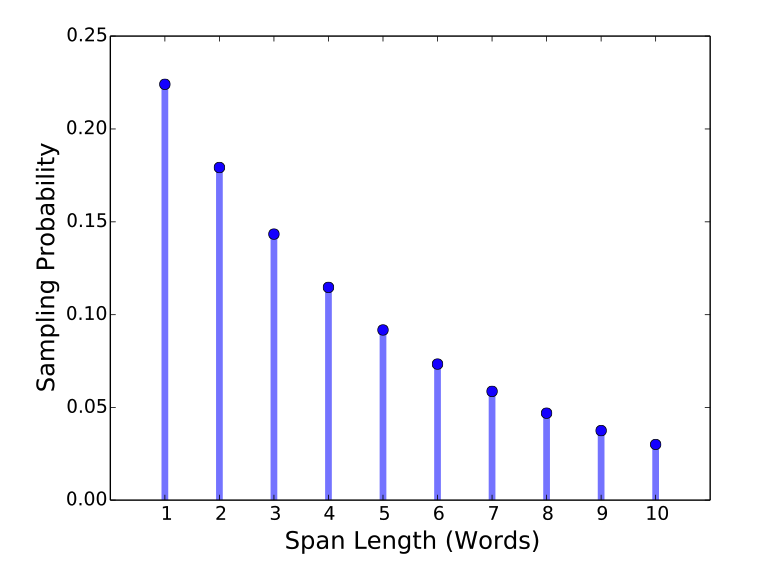
SpanBert的實驗結果: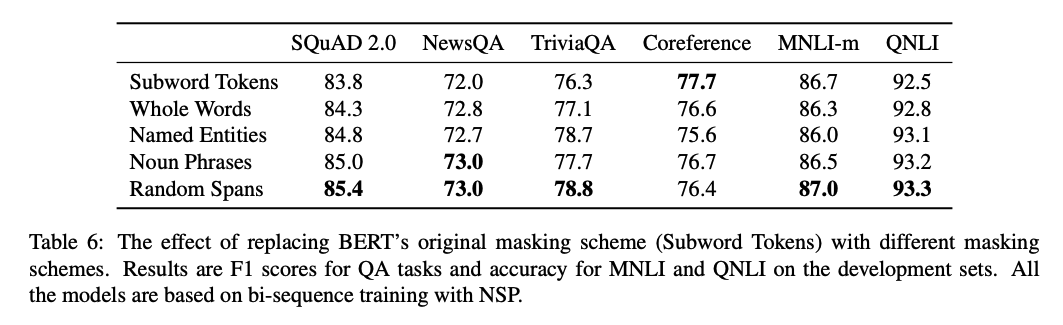
只可惜目前相關的模型還少,可以先取用word masking的模型改善效果:
英文版可以從HuggingFace的pre-trained model找whole-word-masking的模型
https://huggingface.co/transformers/pretrained_models.html
中文的話,可以用ymcui放出的pre-trained model
https://github.com/ymcui/Chinese-BERT-wwm#
改變Masked的比例
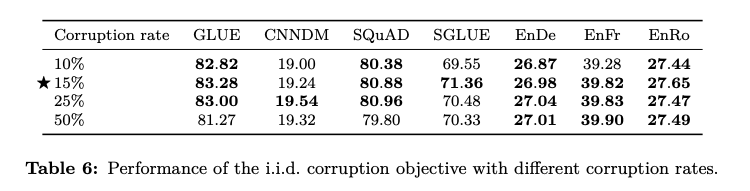
Google的T5嘗試不同masked的比例,探討最好的參數設定是什麼。很剛好的,Bert原始設定的15%就是最佳的選擇:
NextSentencePrediction 👎?
NSP透過預測兩個句子是否為上下文關係,去學句子層級的訊息。在Bert的論文中,可以發現他的效果不是很明顯,甚至在有一些task上面還下降了。
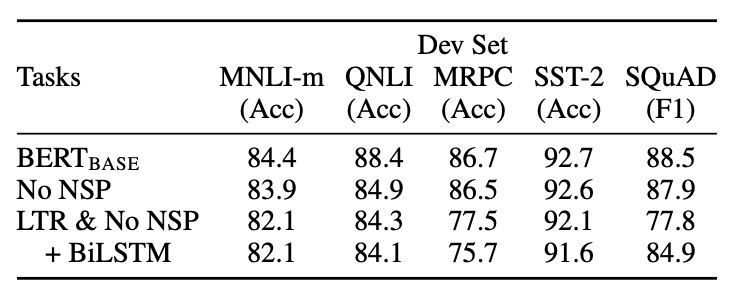
NSP好像效果不太好啊!這馬上成了大家群起圍攻的地方,其後的論文XLNET/RoBERTa/ALBERT也都踩它一腳 XD
RoBERTa
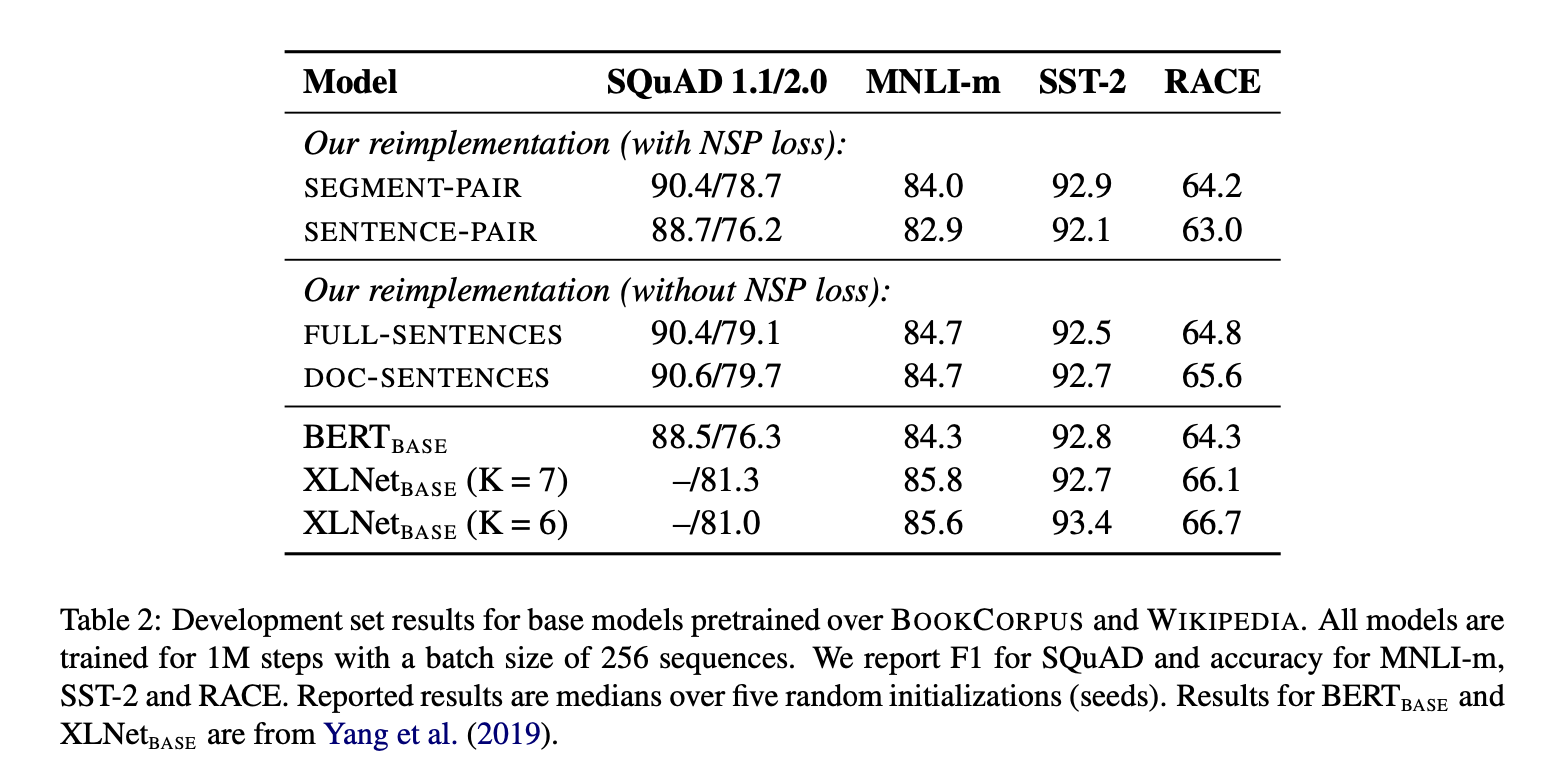
ALBERT
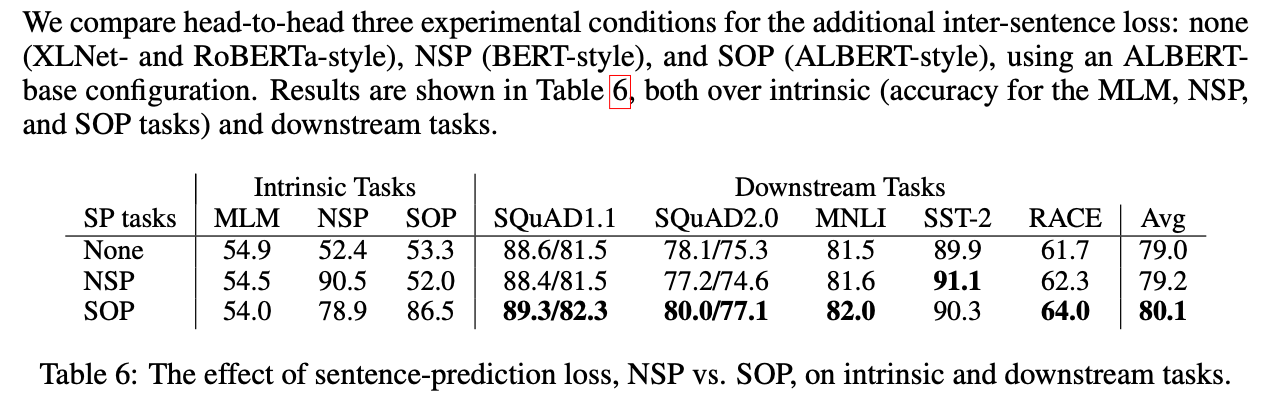
XLNet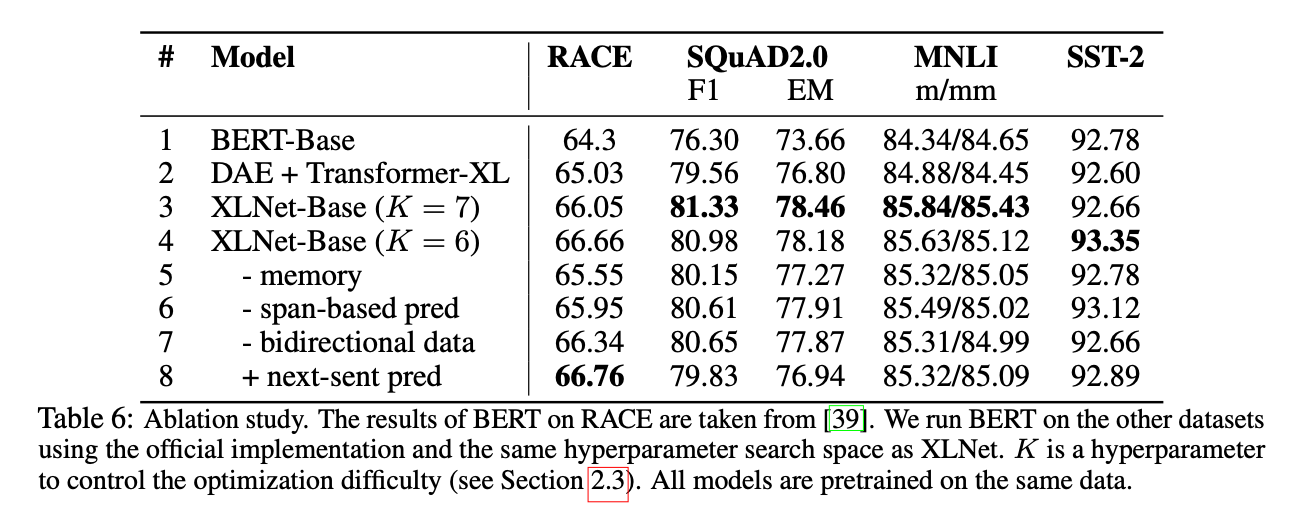
往後的論文也都發現,NSP帶來效果更多是負面的!這可能是由於NSP這個任務本身設計不合理導致 - 作為負樣本的下文是從別的文檔抽樣而來,可能太容易分辨,導致從中學到的東西不多,反而會被這些負樣本干擾到; 再者,NSP讓輸入變成兩個不一樣的句子,缺乏長句子樣本,使得Bert應付長句子的輸入效果不佳。
用Bert來做分類任務的模型,如:BertForSequenceClassification / BertForMultipleChoice
就是基於NSP而來的。由於NSP的效果並不出眾,也是建議改用其他預訓練模型,以取得更好的效果。
其他pre-train task
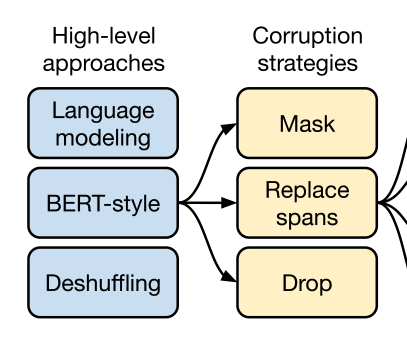
既然NSP效果平平,會不會有更好的預訓練方式呢?大家嘗試了各式各樣的方法,我覺得目前最能總結出各種pretrain task是Google的T5 和 FB的BART
T5所嘗試過的方式

BART所嘗試的方式
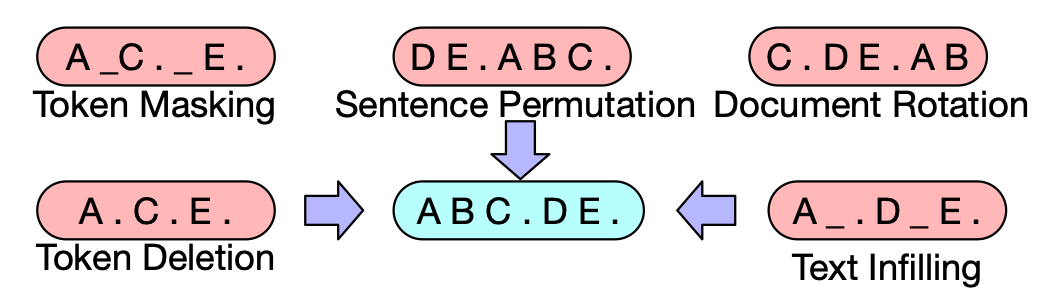
通常language model會作為大家的baseline,之後嘗試有
- 遮住 一些Token,預測遮住的是什麼
- 打亂句子順序,預測正確順序
- 刪掉一些token,預測哪裡被刪掉
- 隨機挑token,在此以後的內容都搬到開頭,預測哪裡才是正確的開頭
- 加入一些token,預測哪裡要刪掉
- 替換一些token,預測哪裡被替換了
實驗的結果如下: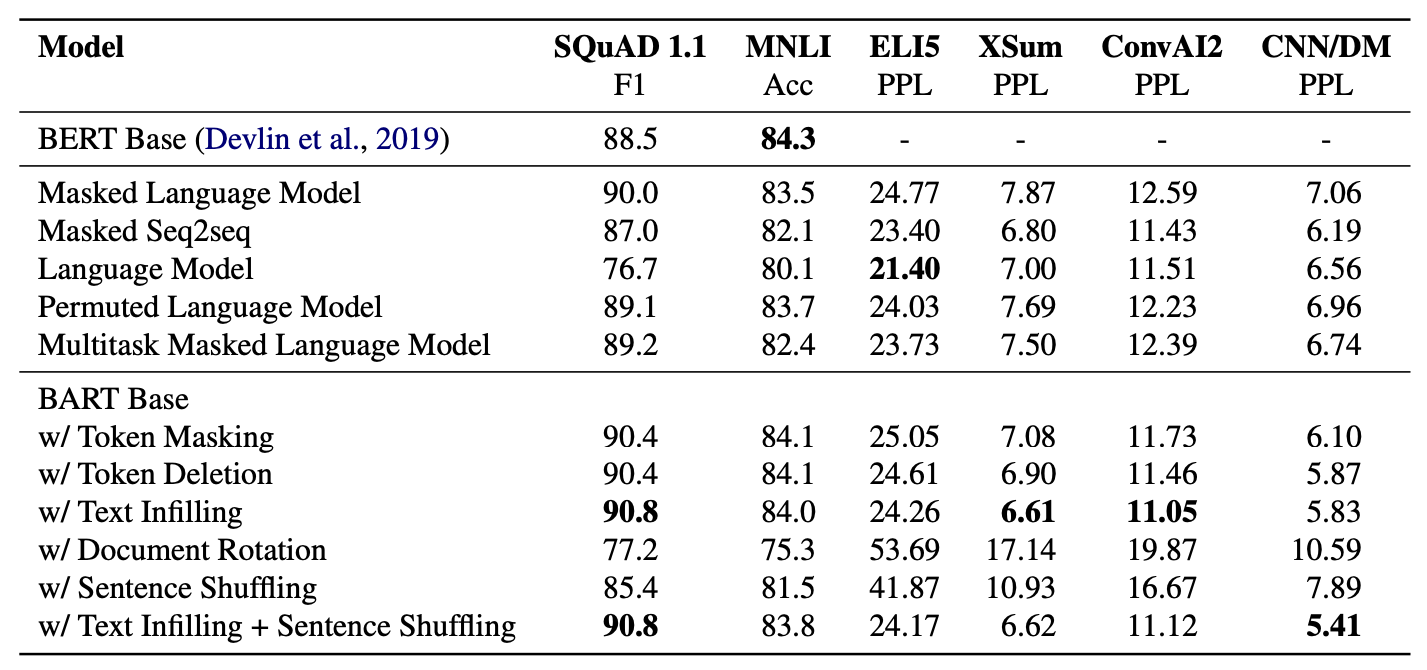
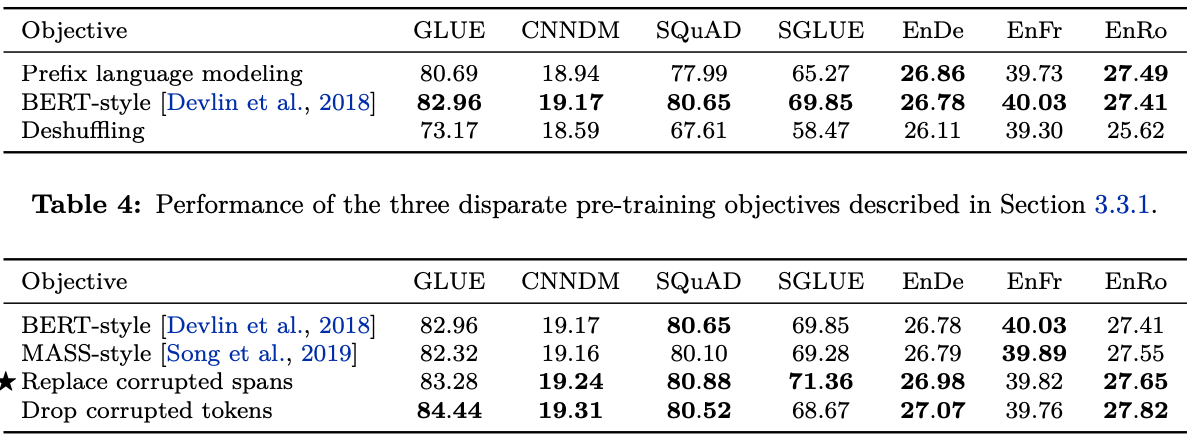
實驗結果發現,好像最原始的MaskedLM就是最好的結果了,要效果更好,用之前提到Span Masking,為了避免洩露出多少字被Masked的訊息,可以只標記一個mask,預測出一個或者多個字的結果
輕量化
Bert的模型很大,為了讓運行時的速度更加快,另一個方向就是輕量化模型。
All The Ways You Can Compress BERT對此做了詳盡的整理。
其中的方向有:
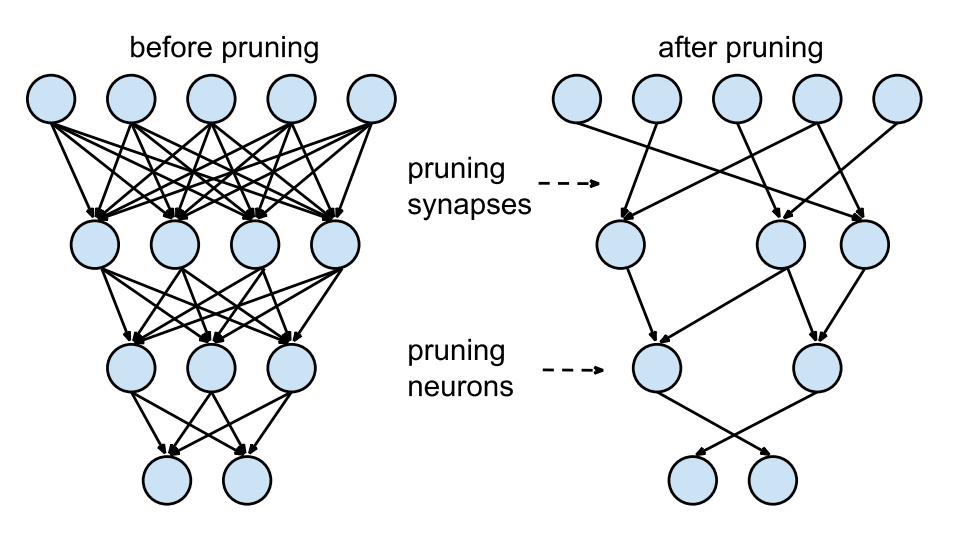
剪枝 - 刪掉模型的一些部分,刪掉某些層,某些head
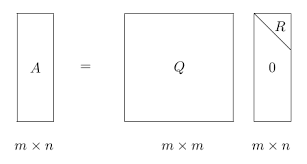
矩陣分解 - 對於詞表/參數做矩陣分解
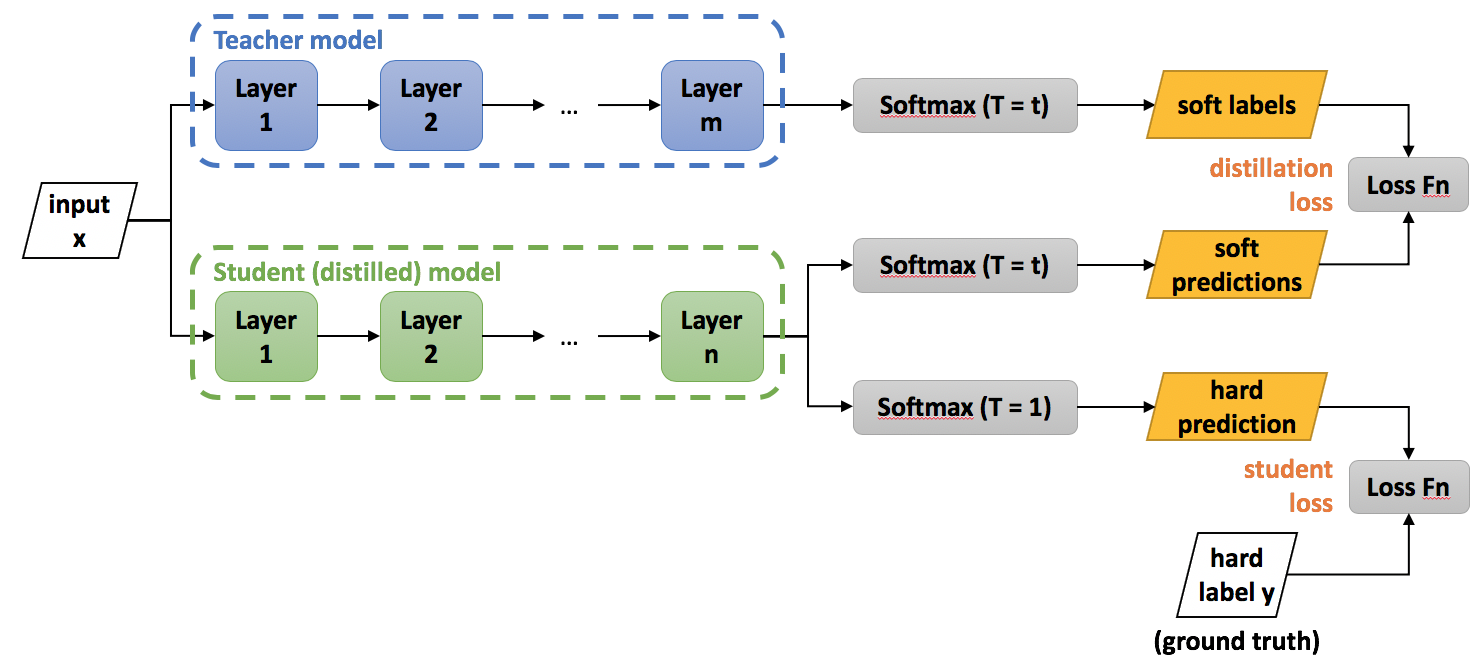
知識蒸餾 - 把Bert的”學識”放到其他小模型上
參數共享 - 層與層之間共用同一個weight
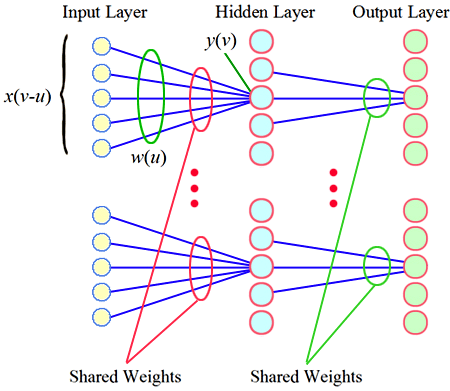
模型及效果可以參考原文
http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
多語言
NLP界的數據集很不平衡,通常是有著大量英文的資料集,其他語言資料相對較少。在繁體中文上,這個問題更加嚴重。由於bert的預訓練方式並沒有語言上的限制,因而其中一個方向,是嘗試將更多語言的資訊放入pre-train模型中,希望在下游任務上,取得更好的效果。
直接可用的就是Google放出來的Bert-Multilingual,它在沒有任何資料的下游任務上,取得結果十分接近中文模型
在Zero-shot Reading Comprehension by Cross-lingual Transfer Learning with Multi-lingual Language Representation Model更是發現,多語言版本的Bert在SQuAD(英文閱讀理解任務)上訓練,拿到DRCD(中文閱讀理解任務)預測,就可以達到與QANet接近的結果;而且多語言的模型,不將資料翻譯為同一語言的結果,會比翻譯要好。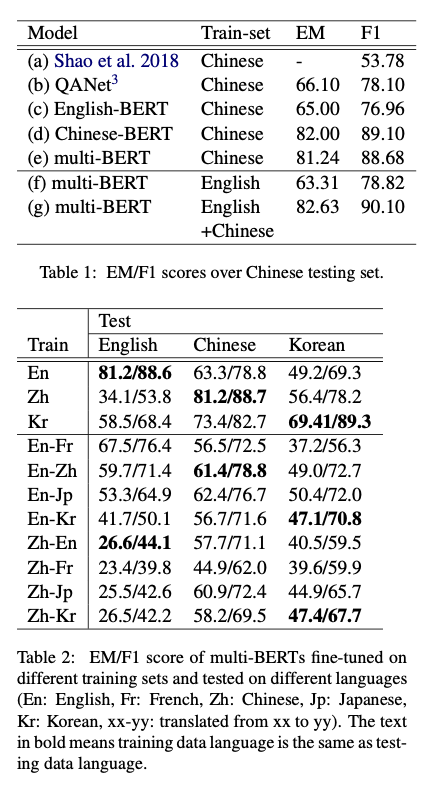
以上的結果,都說明Bert內學會將不同語言的資料連結起來,可能在Embedding,也可能在transformer encoder上
Emerging Cross-lingual Structure in Pretrained Language Models就希望瞭解bert是怎麼把不同語言都關聯起來的。
將不同語言的masklm模型,用這個方式接起來做翻譯任務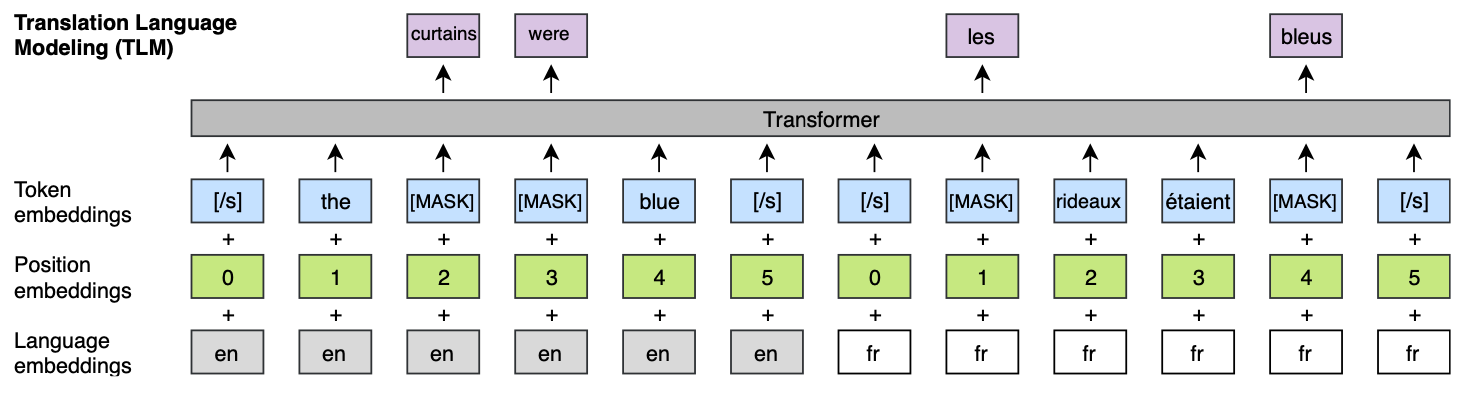
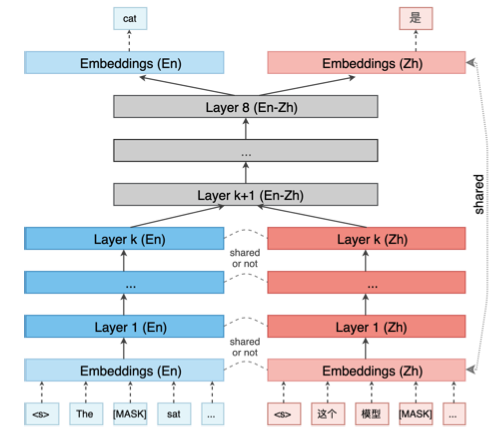
模型之間參數共享是成功的關鍵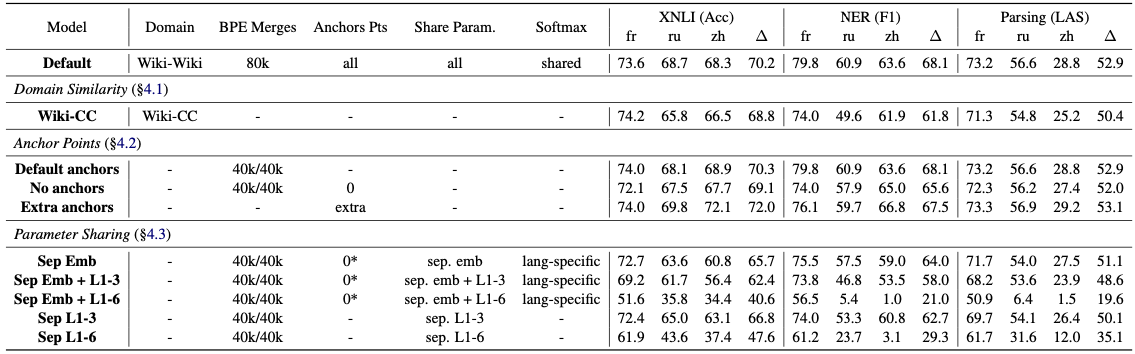
這是因為Bert在背後學到一個詞與上下文的分佈。在不同語言上,同樣意思的詞,上下文的分佈應該是接近的。
而Bert的參數就是學到其中的分佈,使得在多語言遷移上能有如此驚豔的效果。
更大的模型,更好的結果?
儘管Bert已經用了一個很大的模型,但直覺上想,資料越多,模型越大,效果應該越好。因此,就有了一波軍備競賽: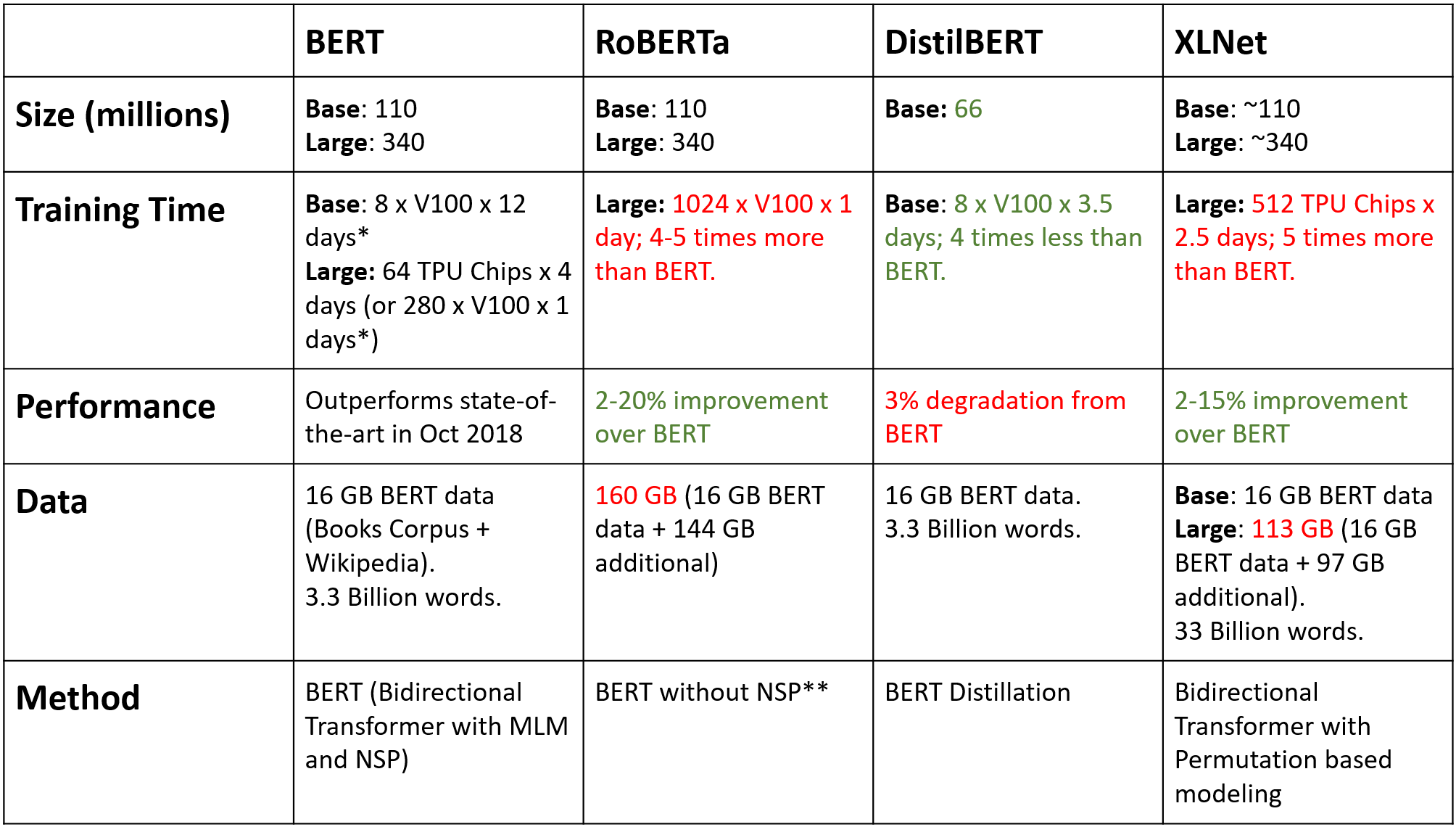
在最近的T5上更是到達極致
但從結果來看,更大的模型好像帶來的增幅,相對資料來說,太小了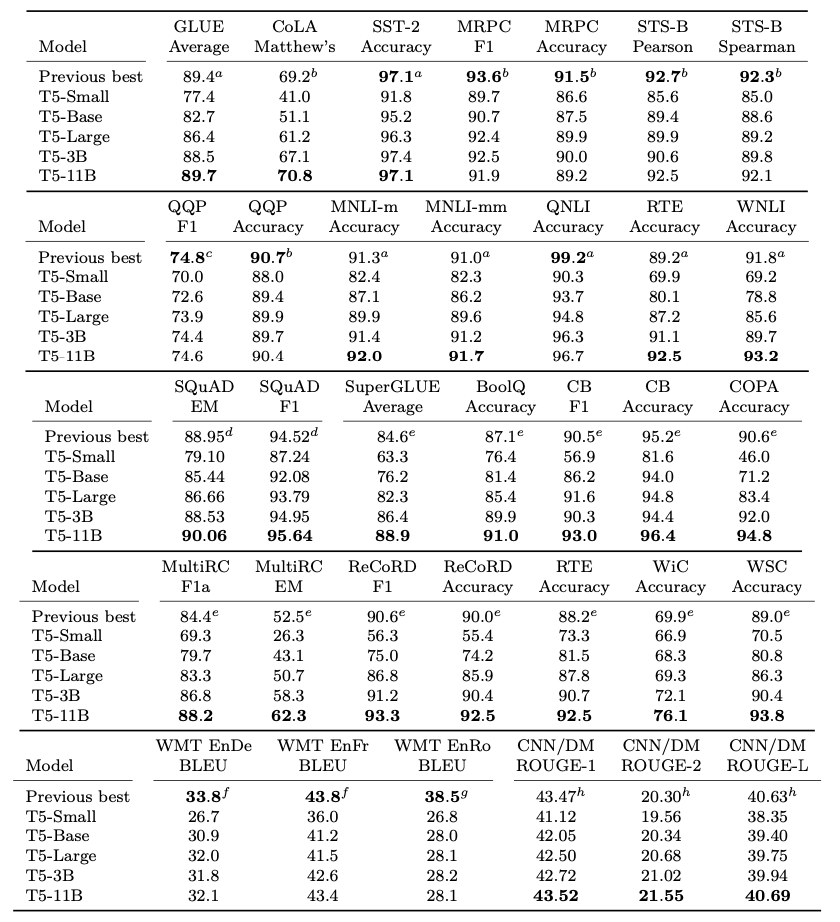
因此,單純增大模型,並不是最有效的方法,用不一樣的訓練方式和目標,也是提升結果的方法。
如ELECTRA就通過新的訓練方式,使得每一個字都會參與到模型中,讓模型更加有效學到representation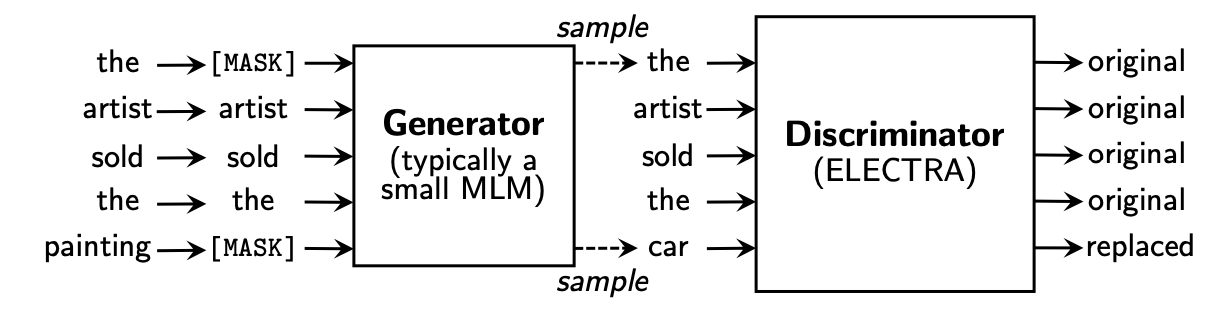
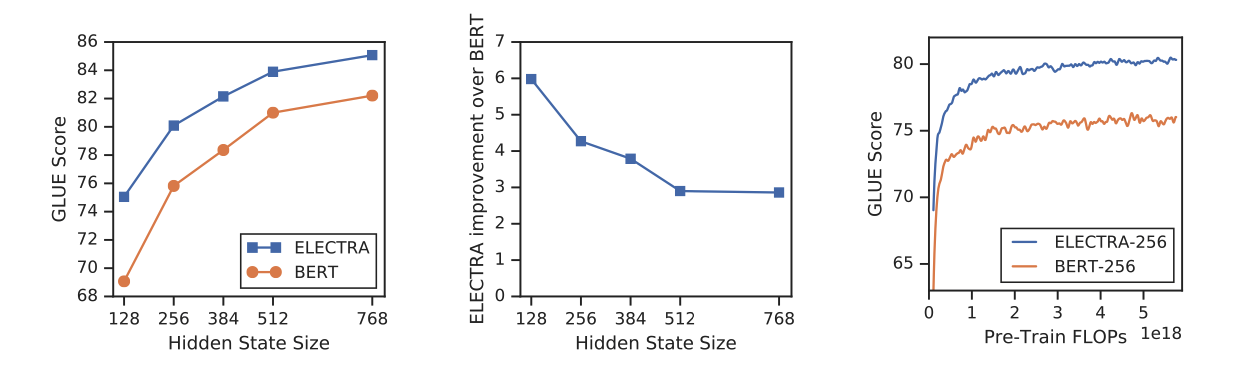
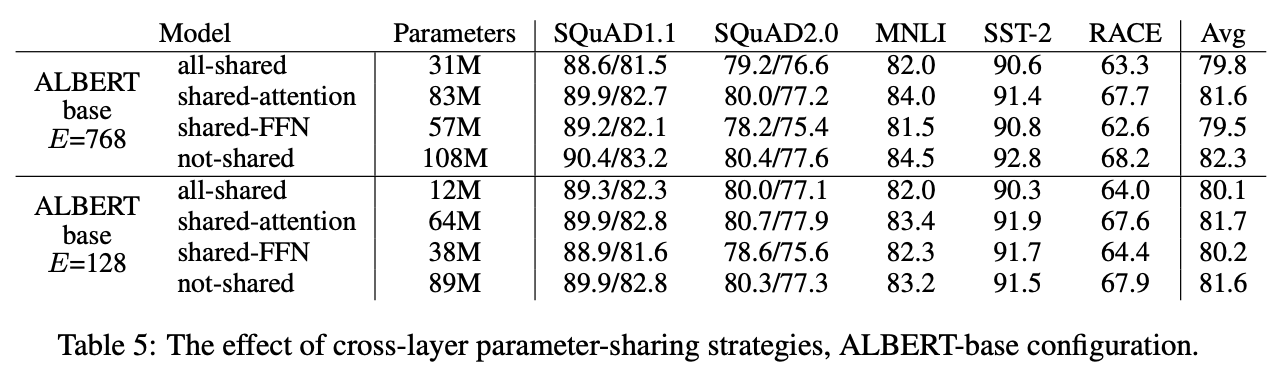
Albert則通過parameter sharing 讓參數量變小的同時,效果沒有大幅度下降
多任務
Bert本身就是一個多任務模型,下游finetune也很自然會用到多任務
之前介紹過**Multi-Task Deep Neural Networks for Natural Language Understanding(簡稱MTDNN)**是怎麼樣做多任務的:
還介紹過十分激進的GPT2:
此後,又有了一個新的多任務方式,相比MTDNN更加簡單暴力,相對GPT2保守而野心勃勃。這就是Google的T5
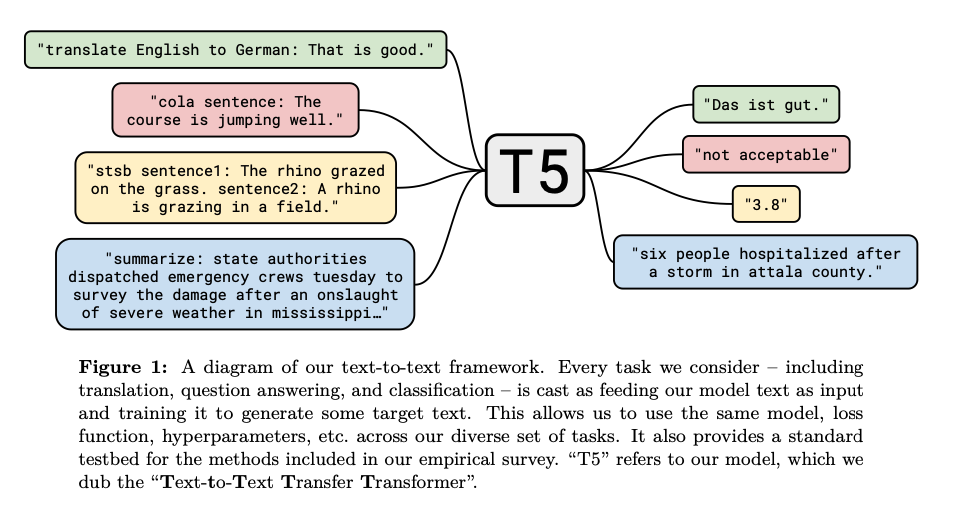
Google的T5採用與GPT2十分類似的想法,訓練生成模型去生成一切文本的答案,但在訓練時,會讓模型知道現在在解不同的任務,同時也跟bert一樣分成訓練和finetune兩個階段。
由於T5過於財大氣粗,導致我們這些平民不太能拿來用。但從他們的實驗結果,可能會找到解決多任務問題的一些啟示:
目前多任務要注意到資料之間不平衡的問題,任務之間的資料量是不一樣的,導致模型對於某些資料量少的任務表現不佳。
其中一個方法,是sampling,減少對資料量大的資料取樣,增加對少資料的取樣。其中一樣例子,便是Bert在訓練多語言時,便是如此取樣:
To balance these two factors, we performed exponentially smoothed weighting of the data during pre-training data creation (and WordPiece vocab creation). In other words, let’s say that the probability of a language is P(L), e.g.,P(English) = 0.21 means that after concatenating all of the Wikipedias together, 21% of our data is English. We exponentiate each probability by some factor S and then re-normalize, and sample from that distribution. In our case we use S=0.7. So, high-resource languages like English will be under-sampled, and low-resource languages like Icelandic will be over-sampled. E.g., in the original distribution English would be sampled 1000x more than Icelandic, but after smoothing it’s only sampled 100x more.
另外一個更加簡單的方法,則是來自T5的實驗結果:
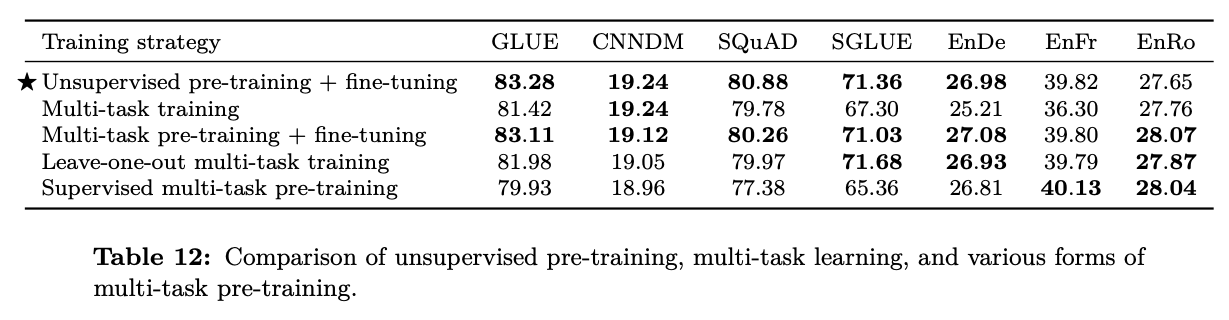
- Unsupervised pre-training + fine-tuning指的是 做完T5的pre-training之後,在各個task上面fine-tune的結果
- Multi-task training 是將T5的pre-training和所有task放在一起訓練,直接在每一個task上驗證結果
- Multi-task pre-training + fine-tuning 則是將T5的pre-training和所有task放在一起訓練,再在每一個task的訓練資料上fine-tune,然後驗證結果
- Leave-one-out multi-task training 是將T5的pre-training和除目標task以外的task做multi-task training,再在目標task的資料集上fine-tune,然後驗證結果
- Supervised multi-task pre-training 就直接將所有資料做multi-task training,然後在各個task上面fine-tune的結果
由此可見,在大量的pertaining資料後,在特定資料上fine-tune可以緩解大量資料pre-training時候,資料不平衡的問題。
相關中文project
Reference
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
SpanBERT: Improving Pre-training by Representing and Predicting Spans
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Cross-lingual Language Model Pretraining
Chinese-BERT-wwm
XLNet: Generalized Autoregressive Pretraining for Language Understanding
ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
RoBERTa: A Robustly Optimized BERT Pretraining Approach
All The Ways You Can Compress BERT
Bert multilingual
Zero-shot Reading Comprehension by Cross-lingual Transfer Learning with Multi-lingual Language Representation Model
Bert Multilingual
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
[DistilBERT](DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter)
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Zero-shot Reading Comprehension by Cross-lingual Transfer Learning with Multi-lingual Language Representation Model
Emerging Cross-lingual Structure in Pretrained Language Models
UNIVERSAL TRANSFORMERS