ACL2020 走馬觀花 - 2 文本生成的新進展
前言
這個系列將會介紹最近研討會的成果,大量地介紹論文,看看他們在解決甚麼問題,有什麼新奇的方法,結果如何。
本篇會介紹以下的論文:
Dice Loss for Data-imbalanced NLP Tasks
Improved Natural Language Generation via Loss Truncation
A Simple, Fast Diverse Decoding Algorithm for Neural Generation
Dice Loss for Data-imbalanced NLP Tasks
https://arxiv.org/abs/1911.02855
類別不平衡,甚至到負樣本太多的情況,會使得模型花費過多的心思去調整。比如將大量樣本的機率從0.8調整到1,其實意義不大 - 我們在預測的時候,只會關注最高項的機率。
因此重點就是,確保最高項機率比別的選項高,就不需要更新下去了。
從dice loss 視覺化也可以看到,x軸是正確項的預測機率,y軸是loss。loss會在預測機率是0.5的時候到達最小,意味著確保目標項會比其他項高(二分類以上才合理,二分類在這個loss上應該完全學不到東西)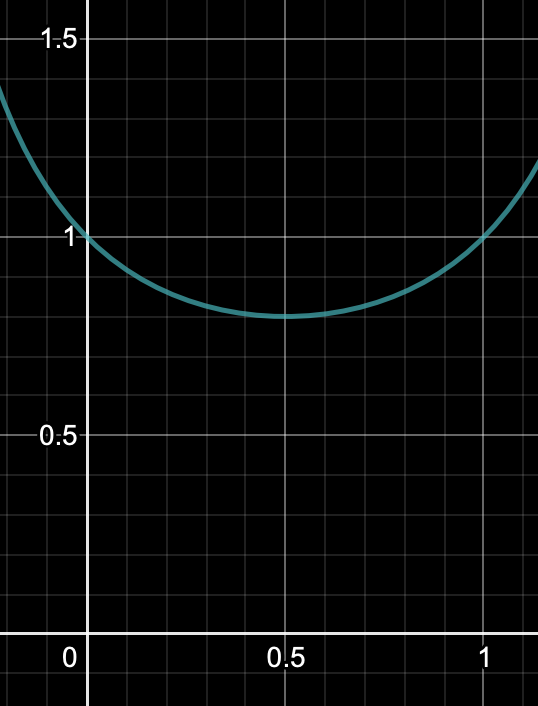
想要試看看的話,這裡有pytorch版的CODE
class DiceLoss(nn.Module):
"""DiceLoss implemented from 'Dice Loss for Data-imbalanced NLP Tasks'
Useful in dealing with unbalanced data
Add softmax automatically
"""
def __init__(self):
super(DiceLoss, self).__init__()
def forward(self, y_pred, y_true):
# shape(y_pred) = batch_size, label_num, **
# shape(y_true) = batch_size, **
y_pred = torch.softmax(y_pred, dim=1)
pred_prob = torch.gather(y_pred, dim=1, index=y_true.unsqueeze(1))
dsc_i = 1 - ((1 - pred_prob) * pred_prob) / ((1 - pred_prob) * pred_prob + 1)
dice_loss = dsc_i.mean()
return dice_loss結果:
在NER/MRC等各類型的task上均有提升(DSC)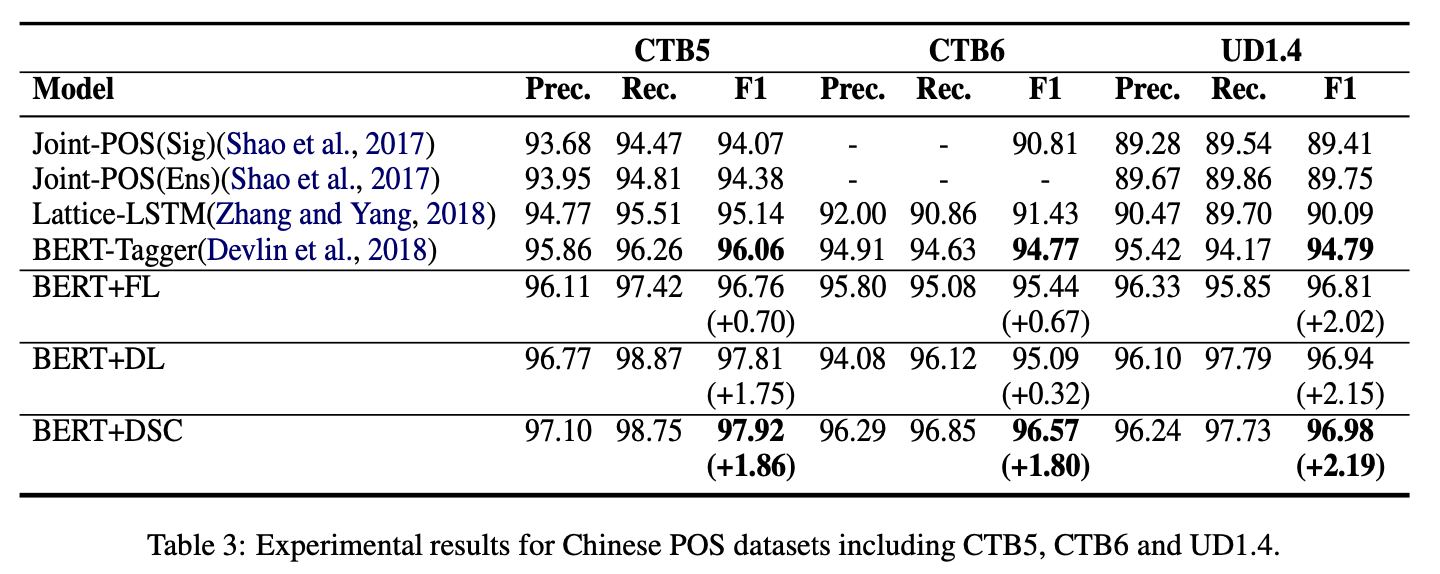
思考:
- 比focal loss有更狠的懲罰,個人嘗試幾個資料集效果都不太好,還是需要根據資料的情況去使用啊。
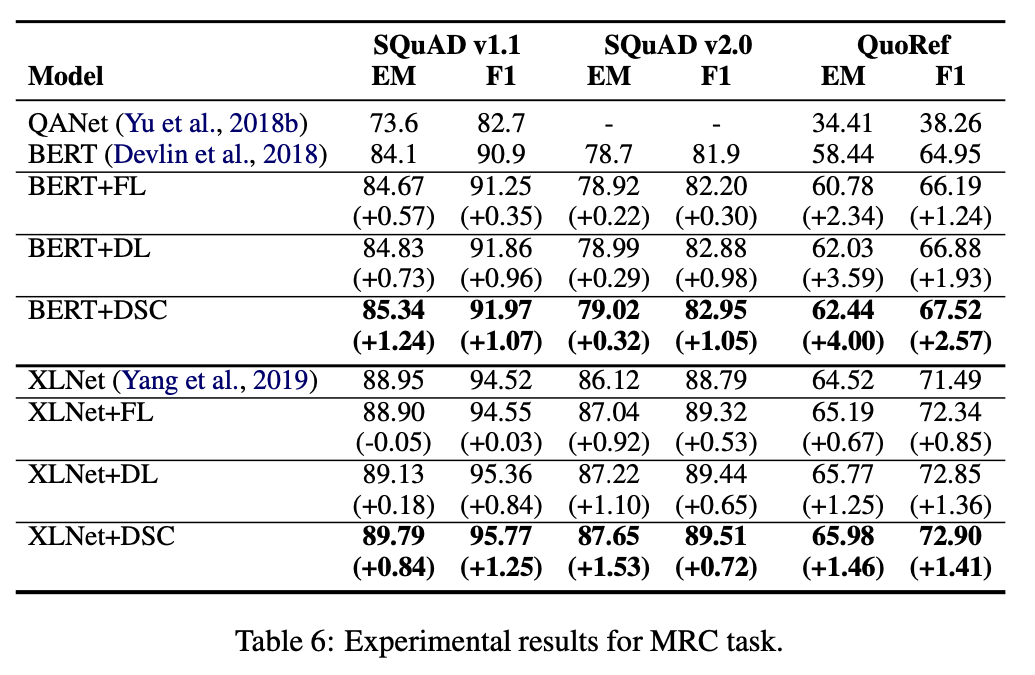
Improved Natural Language Generation via Loss Truncation
https://arxiv.org/abs/2004.14589
文本生成的過程,是在根據上文去生成下一個字,有時候並不會只有一個結果,比如 一個 後面可以接不同的字。用最小化log loss的方式調整模型方向的話,會導致模型很容易被其他結果影響到。
如下圖,reference是混合兩個高斯分佈的線,我們嘗試用一個高斯分佈的線去fitting它(模擬模型的預測),最小化log loss的方式會得到綠色虛線的結果,意味著模型被其他可能性帶走了。而我們更加期望的,應該像是Min distinguishability這條線一樣,關注在機率更高的樣本上。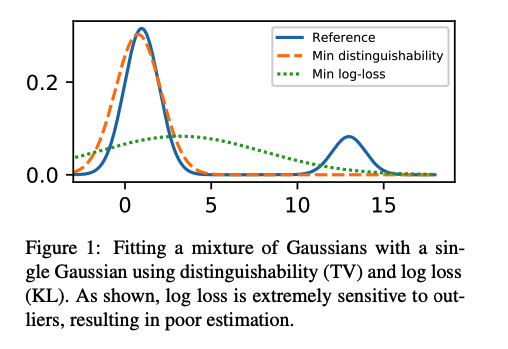
論文提出的解決方法也很簡單,既然模型會被機率更低的樣本帶走,那就把這些機率低的樣本拿掉就好。
細節部分看code比較好懂,原文的數學實在太難啃: https://github.com/ddkang/loss_dropper
方法是將每一筆資料的loss都存在list裡面,到10000筆之後,從小到大排序,取某個百分比分位數,如60%位置的數作為threshold,大於這個threshold的loss都直接變0這樣。
經過loss truncation的生成模型,抗干擾更強,還可以避免一些非事實的生成。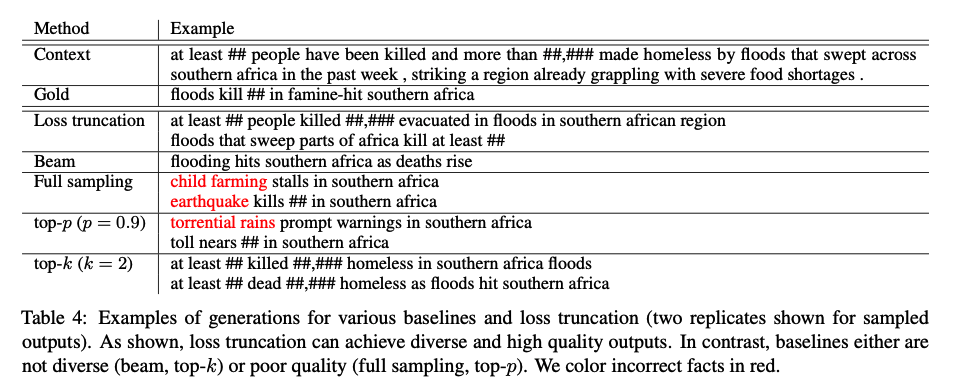
A Simple, Fast Diverse Decoding Algorithm for Neural Generation
https://arxiv.org/pdf/1611.08562.pdf
Beamsearch的結果不夠多元化,很多時候是前文句子一樣,後文稍有變化,導致整體看起來變化不大。
因此,需要給前文的高機率的詞一些懲罰,使得其他結果有機會被納入進來。
這個懲罰呢,就是按照機率高到低的順序,最高項為-1,次高項為-2這樣,使得同一個輸入的候選結果被懲罰,越不容易選到同一個輸入的候選詞。
這個懲罰同時會加一個參數$\gamma$,來控制每一個list的懲罰力度(如圖中的$\gamma$為1)
我們希望這個參數可以自適應得到,論文也提出一個運用強化學習來的到自適應的參數。
結果:
論文結果也可以看到,beamsearch的多樣性有效提升了~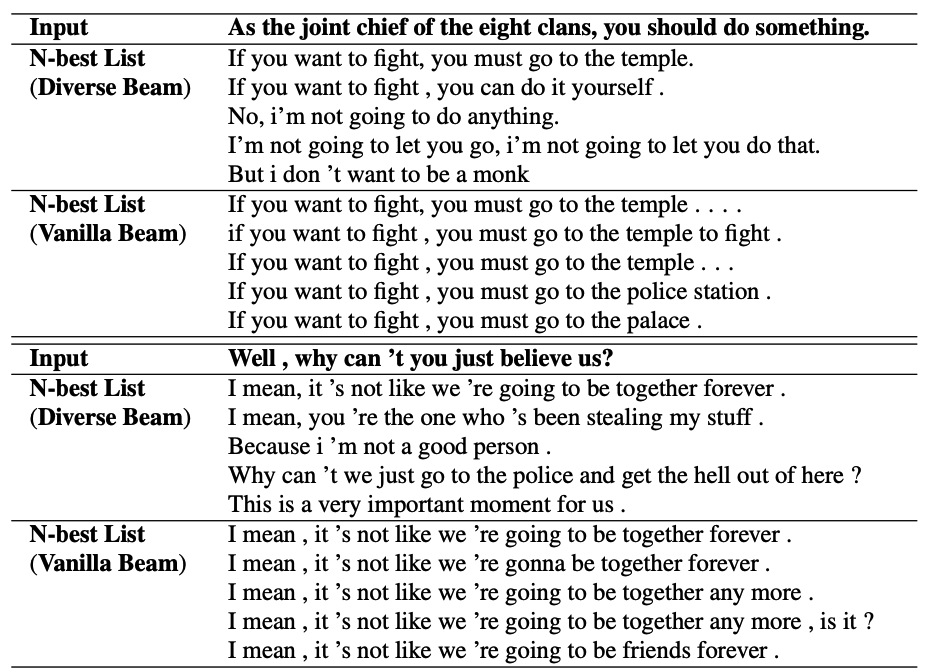
思考:
其實也可以算token的overlap,當超過threshold時從beamsearch中拿掉,也可以做到多樣化的效果。