Contrastive Learning - BYOL的爭議
這幾年的研究證明,一個好的預訓練方式可以讓你的模型事半功倍。究其原因,我們在訓練的網路基本上是在做兩件事情,將資料放到一個空間裡面,然後將其劃分開。
在沒有預訓練的時候,資料會隨機分佈在空間裡面,需要經過更多的時間才能很好將資料劃分開來。
而預訓練則是提前學好怎麼把資料放到空間合適的位置中,後續便不需要做太多調整就可以將資料劃分開。
這樣看來,預訓練的重點在於將資料放到空間裡面,同時讓相同性質的資料接近:
要做這個預訓練模型,資料越多效果越好,因此有標籤的監督式學習並不合適。無監督學習的話,通常是將資料壓縮/破壞再還原為本身。然而還原這個過程,是需要很多細緻的調整,這些調整對於將資料放到空間中並沒有太大的作用,也使得還原的任務需要更多時間收斂。
因此Contrastive learning就是提出一個更高效的預訓練方式,不需要還原本身的樣子,而是通過辨別資料的相同跟相異之處去達到同樣的效果。
在年中時候也介紹過 Contrastive learning 的 SimCLR,SimCLRv2,BYOLSelf-supervise learning 的新方向 - 從 representation 中下手
在本文裡,就看一下經過半年以後,Contrastive learning有甚麼新的故事
- 5 step of contractive learning
- BYOL的normalization爭議
5 step of contractive learning
在 A Framework For Contrastive Self-Supervised
Learning And Designing A New Approach 裡面總結了contrastive learning 的5個step:
(1) Data Augmentation Pipeline
一個樣本中透過資料增量的方式,生成多個樣本
(2) Encoder
將資料變成向量,圖片的話可以用ResNet,也可以從0用搭建encoder的網路。
(3) Representation extraction
決定要從encoder取出那一個部分,去做相似比對。
(4) Similarity measure
資料相似度比對的衡量方法。基本上都是用dot product。
(5) Loss Function
將正樣本拉近,和推遠負樣本。
BYOL 的 batch normalization 爭議
contractive learning 需要不少有難度的負樣本才能有效學到特徵,因此數量以及品質會影響到預訓練的效率和結果。而BYOL提出將負樣本去除,也可以做contractive learning的方法:
要做的事情是將網路分成一個兩個部分,一個是目標網路,一個是加noise的目標網路,而這個noise是之前結果的指數移動平均。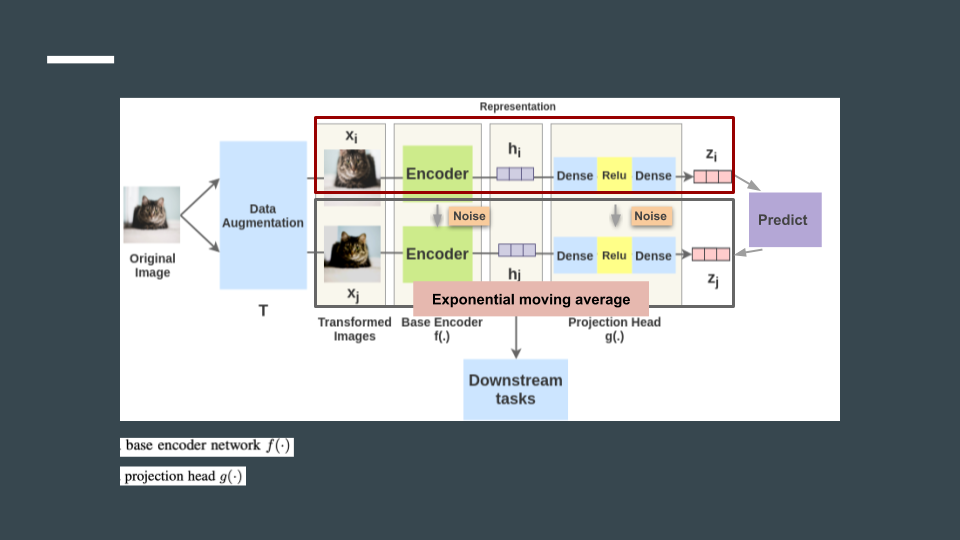
目標從預測哪一個是原圖,變成還原加了noise的 $Z_{i}$。
而有實驗發現,BYOL有效的關鍵是在於 Batch normalization!如果去掉batch normalization會讓效能大幅度下降!
其中batch normalization會用在encoder之後的projector上。
而Normalization要做的事情,是將值縮放到一個範圍,而通常這個範圍要符合均值0,標準差1。這樣做的原因,常見的理解是為了減少底層網路更新對後續網路的影響(Internal Covariate Shift)。
從實驗來看, 在encoder有BN的情況下, 雖然有所減弱,但影響不算大. 確實BYOL在沒有BN的情況下效能都大幅度減弱.
但只在最後一層加BN,也可以讓一定程度上保留模型的能力.這次的normalization是用在最後兩層,這看起來不是在解決Internal Covariate Shift的問題啊?
所以到底batch normalization發揮了甚麼作用?
我們剛剛只提到normalization,而Batch normalization是指說normalization的對象是batch,縮放的均值和標準差是調整的是一個batch的資料。
還值得注意的是,同一筆資料,經過batch normalization之後也會得到不一樣的結果(同一個batch的資料不一樣,均值跟標準差的調整也會不一樣)
因此, 在 Understanding self-supervised and contrastive learning with “Bootstrap Your Own Latent” (BYOL) 中就猜測一筆資料在不同batch時候會有不一樣的結果,就是不言而喻的negative sample, BYOL本質上並沒有去掉negative sample.
而 BYOL works even without batch statistics 則有不一樣的看法,batch normalization的作用讓網路有合適的初始化,訓練更加穩定(值不會跑得太跳,太遠)
要確定BN到底是穩定參數還是隱含負樣本, 我們可以嘗試不用BN, 用data dependent的方法穩定參數,看看效果是否還能保持, 以此推斷BN的作用.
Modified init和 GN+WS 都是不用batch的統計,穩定參數的作法.實驗結果來看,都還是能讓模型有一定的分數.這也似乎說明, BYOL中batch normalization的作用讓網路有合適的初始化這一觀點.
在BYOL的論文可以看到,batch size減少效能也沒有大幅度下降(4096 到 128 accuracy 差不多 -3的樣子), 如果背後真的是仰賴BN帶來的negative sample, batch size的改變應該會帶來更大的負面效果(batch size 越小, batch normalization 越不準)
CODE
https://pytorch-lightning-bolts.readthedocs.io/en/latest/self_supervised_models.html
Reference
A Framework For Contrastive Self-Supervised Learning And Designing A New Approach
Supervised Contrastive Learning
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
understanding-self-supervised-contrastive-learning
BYOL works even without batch statistics
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift